
Sometimes, it’s a case of not so much needing a guru as you do someone who exposes information for the smart people you already have. Like the DBA.
Introduction
Some years back, when Sun was still alive, I was part of a big capacity planning project with an industrial customer. The economy wasn’t super good, but they planned to either grow if the economy went up, use their cash to do a few mergers and acquisitions if it went down, or just consolidate a bit if the economy was flat and boring
I was pulled in as a mathematical modeler, as this was a smart customer and wanted proof, not just snazzy demos.
Off to the benchmark center!
We all showed up at the benchmark centre with a replayable script, one of of a busy hour from one of their existing machines running Oracle.
Our plan was to use the script on one of our new machines, by having it run their exact program with larger and larger numbers of simulated users. The benchmark centre had several Sun/Fujitsu M9000s, and even a set of the new dual-core CPU boards.
So we set up run a series of benchmarks, starting at 1000 users and increasing by 500 until we got to 4500.
As we hit 3000 simulated users…
… I posted this prediction from TeamQuest Model on the wall, plus two supporting graphs:


The large graph was the response time increase under load, which is to say, the slow-down. We don’t want it to slow down, so higher is worse.
Quit a bit worse, in fact. It looked like we would slow from 1.3 seconds per transaction to 2.4 seconds, then to 15, then to 25.
Sure enough, the benchmark did start to slow down at 3000 simulated users. 3500 users was worse, and we couldn’t even run 4000, much less 4500.
It definitely was time to swap in the bigger CPUs, as we were planning to support 4500 users on that size of machine.
Ok, faster CPUs will help
The resource usage graph from TeamQuest looked like this, pointing out that at 1500 users we were using more than 30% CPU, then rising rapidly past 50% by 2250 users. At 3000 user we were hitting 100% CPU, and we were out of resources.
But then the Architect said,
“Dave, where’s controller 17?”
The model was made from observations of the real system, and it showed two logical disks but only one controller. Sure enough, we had mounted both disk arrays on one controller, so once we fixed the lack of CPU, the second bottleneck would be controllers.
If we fixed that, the system would then bottleneck on disk.
While we were waiting for the operations team to swap in the new CPUs, we connected the controllers properly, so we wouldn’t have that bottleneck.
We knew that if we eventually did bottleneck on disk, we could widen the stripe.
That’s pretty typical capacity planning: the model tells you what bottlenecks and in which order, so you can build a properly balanced hardware configuration.
And then the DBA said
“Dave, what about db writer?”
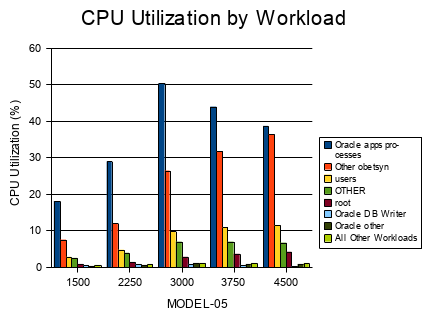
He was looking at the slowdown and cpu used by the “db writer” workload, pale blue in this diagram.
As the load increased, the applications processes (dark blue) rose to use 50% of the CPU, and then, oddly, started to decline. Another processes, the “oracle obestn” group (red) was getting the CPU, and eating the application process’s lunch.
That is suspicious enough, but the DBA noticed that the DB writer was also being starved. The light blue bar was going down, just like that dark blue one.
The Oracle log (journal) writer and db writer use very little CPU, but are critically important. If the journal and the data isn’t written to disk, the database can’t finish updating itself. Eventually everything will grind to a halt, waiting for the writes to complete before any more transactions can finish. But, of course, the writers aren’t getting any CPU!
It turns out that we needed to guarantee the log and DB writers a few percent of the CPU using Solaris resource controls, “cgroups” in Linux parlance.
That was why the benchmarks couldn’t complete at 4000 and 4500 users: the database would end up completely wedged, and stop responding to everyone.
So, just like rebalancing the hardware, we rebalance the available CPU so the DBMS could make best use of what it had. Once that was done, it would still slow down, but it wouldn’t just stop.
Conclusions
I was supposed to be the “guru” and solve their problems, but what I really did was provide understanding:
- everyone saw the need for more CPU,
- the architect instantly saw the controllers and IO were unbalanced, and
- the DBA knew that the CPU was being gobbled up by the wrong processes.
When I shone a bright light on the problem, the customer really solved it themselves.
